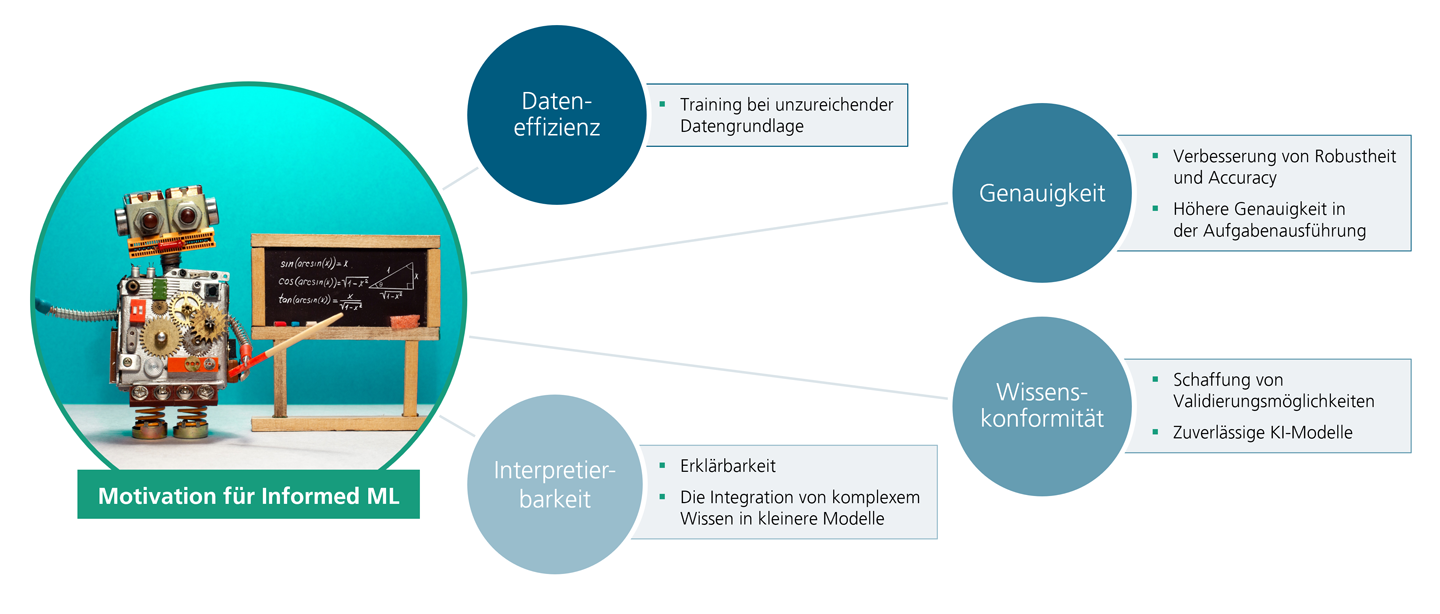
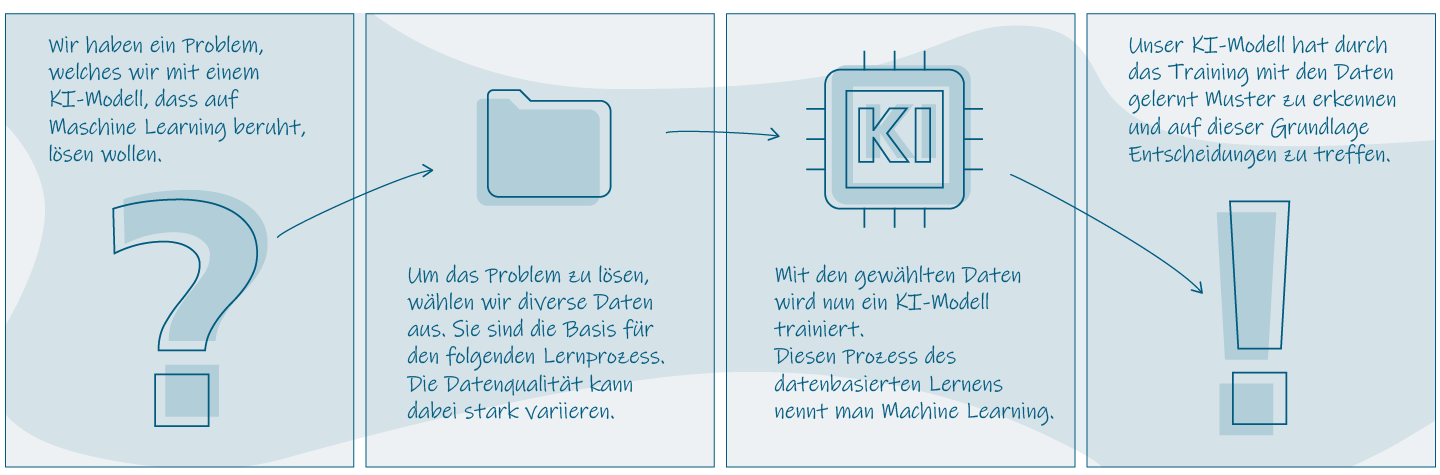
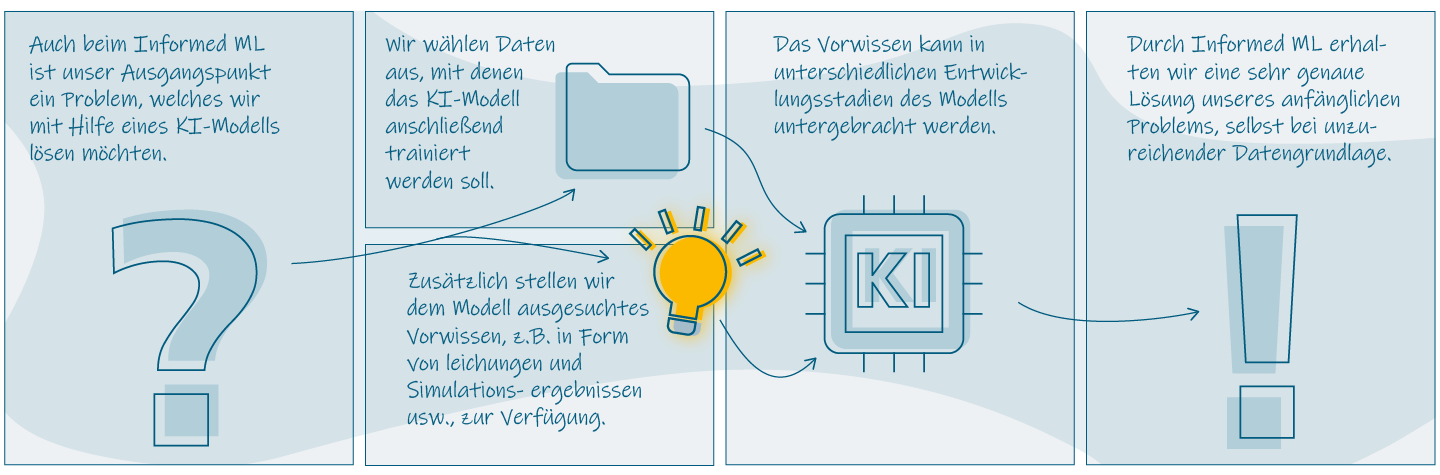
Beim ML lernen KI-Modelle auf Grundlage von Trainingsdaten, um später den gewünschten Output zu generieren. Dabei hängt die spätere Qualität eines Modells besonders von der Qualität der zur Verfügung stehenden Trainingsdaten ab. Je hochwertiger die Daten, desto zuverlässiger das Modell. Dieser Umstand ist dem Prozess des ML geschuldet: Beim ML beginnt man mit einem Problem, welches man mittels KI lösen möchte. Man ermittelt Daten, die das Modell braucht, um eine Problemlösung zu erlernen. Mit diesen Daten wird anschließend das Modell trainiert, bis man zur Lösung gelangt. Abschließend erhält man ein KI-Modell, welches eigenständig Problemlösungen nach den erlernten Mustern generieren kann. Bei einer tiefergehenden Betrachtung dieses Konzeptes offenbaren sich Schwächen. Ein großes Problem stellen in der Regel die Trainingsdaten selbst dar. In vielen Branchen und Bereichen unseres Lebens ist es schwer qualitativ hochwertige und mengenmäßig ausreichende Daten zu erhalten. Das kann diverse Gründe haben; beispielsweise ist es sehr kostenintensiv, Geodaten durch Drohnenaufnahmen zu gewinnen, da dafür teures Equipment notwendig ist.
Weitere Beispiele sind Daten, die nur durch komplexe Experimente entstehen oder historische Daten, die nicht mehr verfügbar sind. Wenn es um die Arbeit mit vertraulichen Daten geht, die personenbezogene Informationen oder Unternehmensgeheimnisse enthalten, unterliegen diese in der Regel besonderen Auflagen und Bedingungen. Ein KI-Modell, dass auf ML basiert, steht und fällt mit seinen Daten. Durch sie lernt das Modell –man könnte sie auch als Wissensgrundlage eines Modells betrachten. Unzureichend vorliegende Daten haben negative Folgen auf die Genauigkeit eines Modells. Die Genauigkeit bezieht sich dabei auf die eigentliche Performance eines Modells. Wie akkurat werden die späteren Aufgaben erfüllt? Neben der Frage nach Dateneffizienz und Genauigkeit offenbaren sich Schwächen des ML auch bei Themen wie Wissenskonformität und Interpretierbarkeit.
Der Ansatz der Wissenskonformität bewegt sich thematisch in die Richtung einer vertrauenswürdigen KI. KI-Modelle können im Laufe ihres Trainings unterschiedliche Formen von Verzerrungen, auch Bias genannt, entwickeln. Ein Bias kann zum Beispiel durch die Vorauswahl der Trainingsdaten entstehen, durch die Programmierung des Algorithmus, oder durch Zweckentfremdung eines Modells auf Grund des Einsatzes in einem neuen Kontext. Modelle, die einer oder mehreren Formen eines Bias unterliegen, sind nicht mehr vertrauenswürdig, da sie verzerrte Ergebnisse generieren. Das Problem ist jedoch nicht nur die eigentliche Verzerrung an sich, sondern auch deren Detektion. KI-Modelle werden immer größer und komplexer, dass macht die Interpretation der Modelle stetig schwieriger. Es ist von außen immer weniger nachzuvollziehen, wie ein Modell zu welchem Ergebnis kommt.
 Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS
Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS