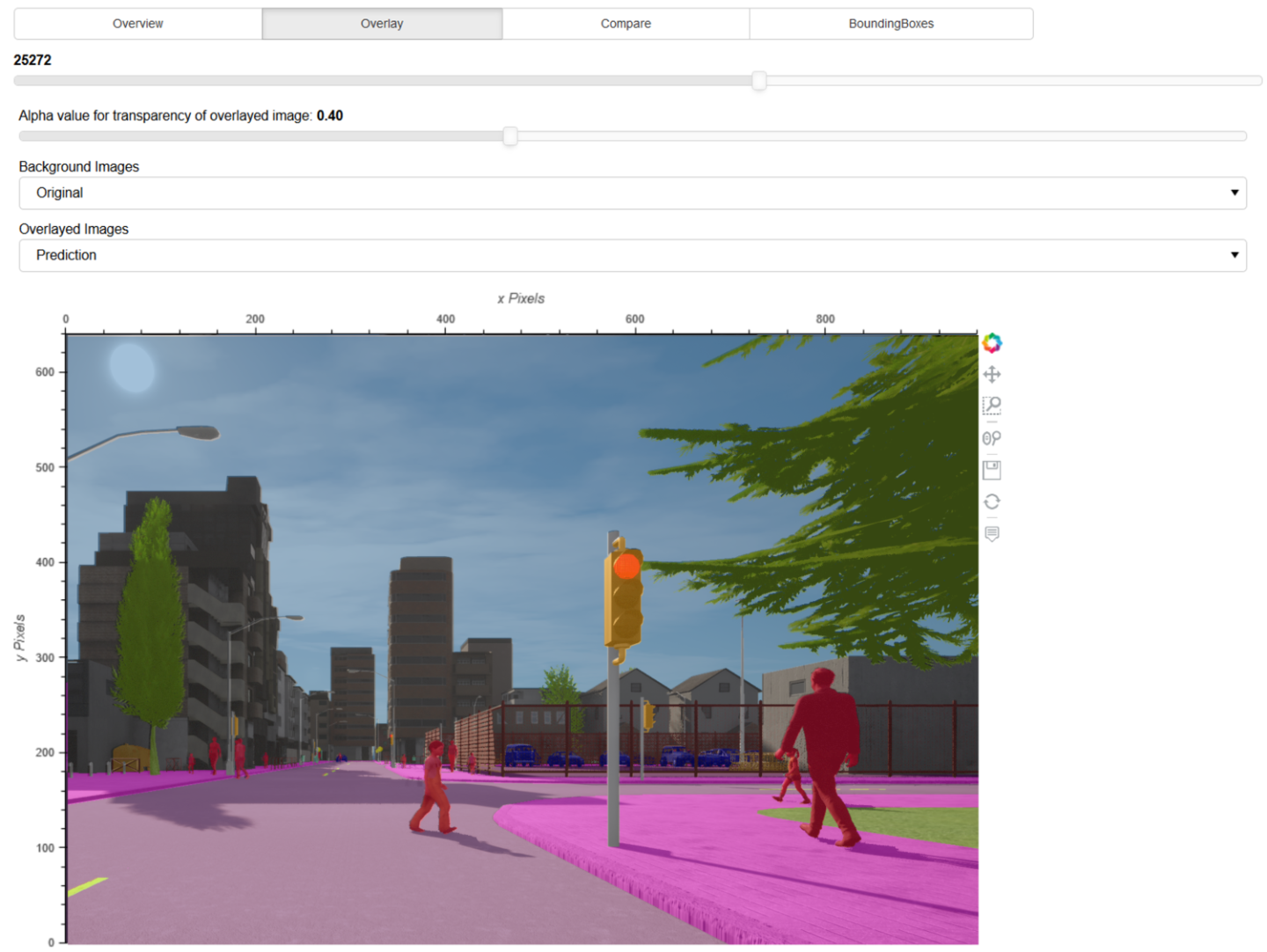
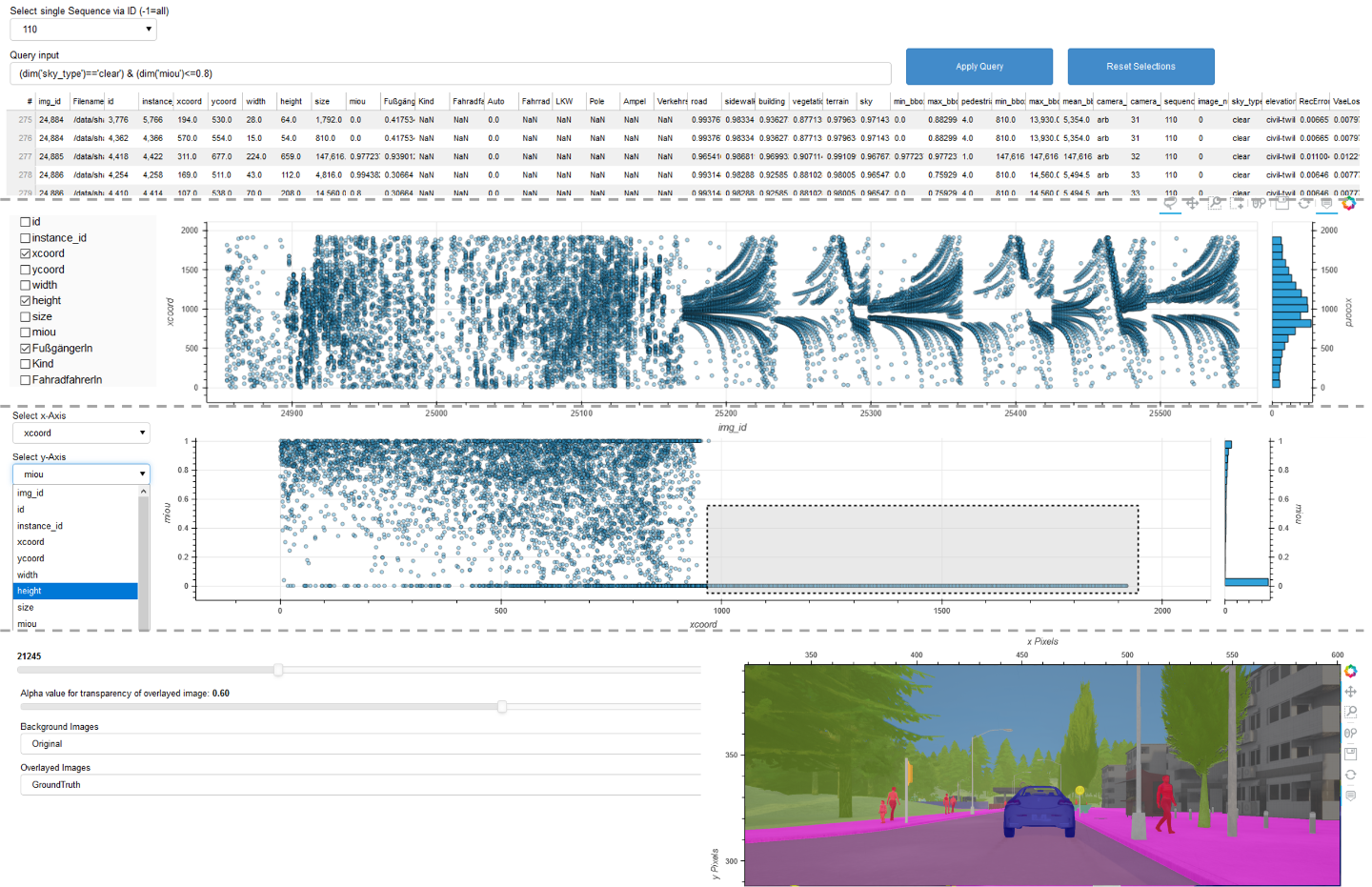
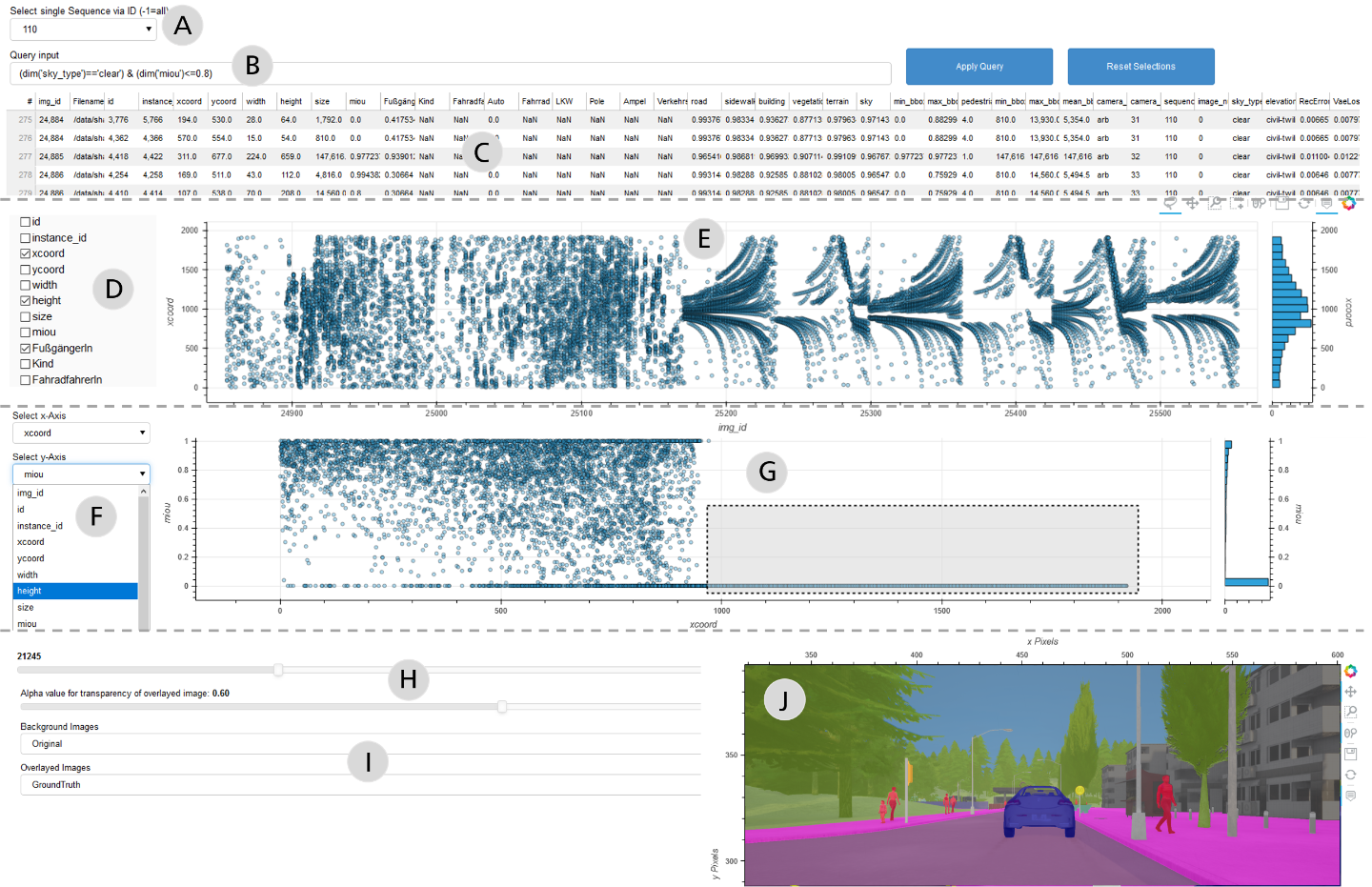
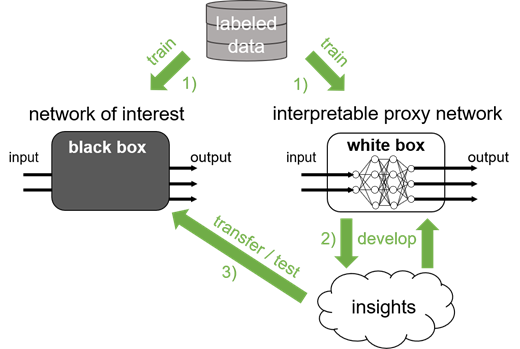
CARLA verknüpft Simulation-Based Testing mit einem semantischen Konzept, um das Verhalten von KI-Elementen für Menschen verständlich aufzubereiten und somit prüfbar zu machen. Wie funktioniert das im Detail?
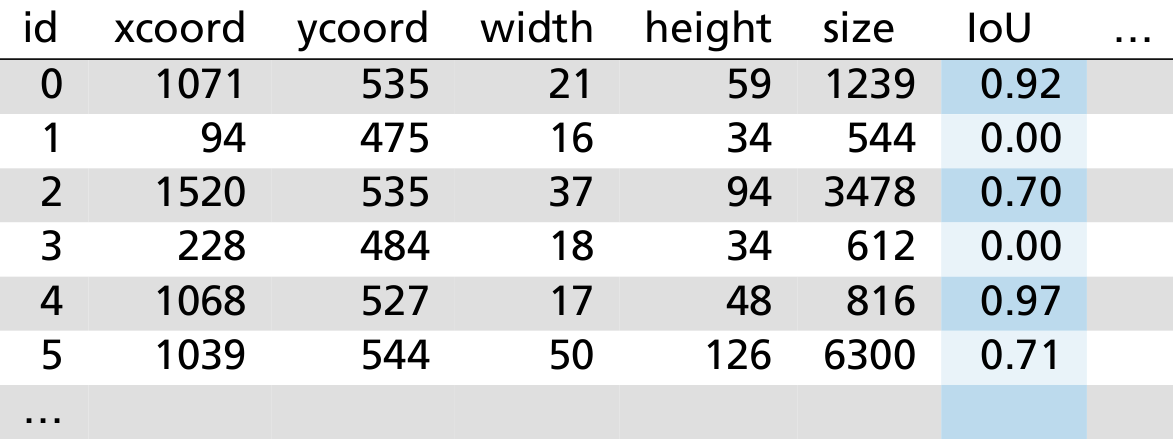
In KI-Anwendungen können verschiedene Methoden des Maschinellen Lernens zum Einsatz kommen, wie z. B. tiefe neurale Netze (Deep Neural Networks, kurz: DNNs). Üblicherweise werden diese auf Real-Welt-Daten trainiert und mit einem Prüfdatensatz (Hold-Out) bewertet, woraufhin die mittlere Performanz (Mean Intersection over Union, kurz: IoU) angegeben wird. Auch wenn das Modell audiovisuelle Daten wie z. B. Videos auswertet, wird daraus ein Durchschnitt berechnet. Für den Einsatz in sicherheitskritischen Anwendungen wie dem Autonomen Fahren ist diese Bewertung höchst unzureichend.
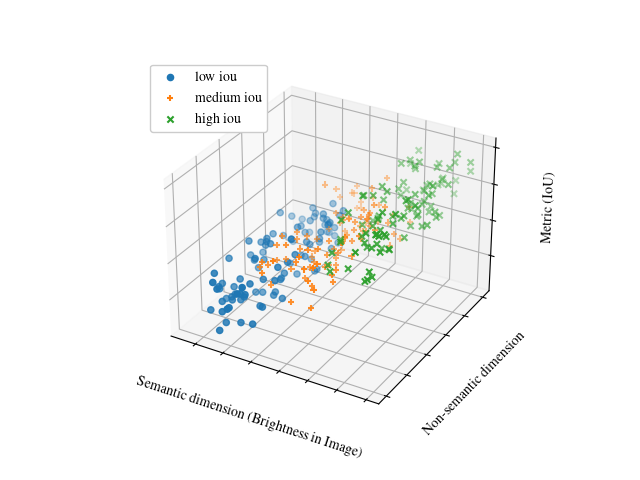
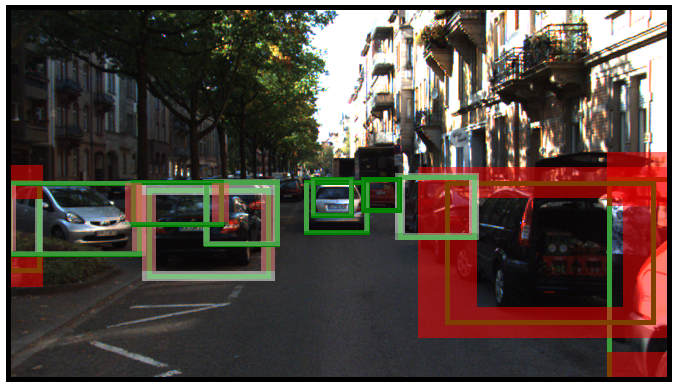
Das semantische Konzept mit CARLA geht anders vor: Anstatt die mittlere Performanz als Solches zu betrachten, wird die mittlere Performanz gesondert pro Bild berechnet und ein spezifischer Aspekt beurteilt, wie z. B. die Helligkeit des Bildes. Semantisches Testen erlaubt es hier, Situationen mit unterschiedlichen, teils höchst seltenen Helligkeiten (z. B. aufgrund von stark reflektierenden Oberflächen) von einer ansonsten unveränderten Verkehrsszene zu erzeugen. Der Helligkeitskontrast dient hierbei als Erkennungsmerkmal, daher liefern Bilder, die z. B. tagsüber mit ausreichender Helligkeit aufgenommen wurden, einen besseren Wert als Bilder, die z. B. nachts aufgenommen wurden. Wird eine solche Korrelation von Helligkeit und Detektionsgüte erkannt, kann untersucht werden, ob sich das neuronale Netz durch zusätzliche Trainingsdaten mit geringerer Helligkeit verbessern ließe.
Auf die gleiche Weise kann auch die Kleidungsfarbe der Fußgänger als semantische Dimension betrachtet werden. Bei ausgefallener Kleidung besteht die Gefahr einer Unterrepräsentation im Trainingsdatensatz, sodass eine geringere Detektionsgüte wahrscheinlich ist. Wenn bestimmte Farbtöne eine signifikant höhere mittlere Performanz haben als andere, ist das eine systematische Schwäche im neuronalen Netz, die behoben werden muss.
Unser Tool CARLA simuliert Verkehrsszenen und das Verhalten von Verkehrsteilnehmer*innen und erzeugt dafür die entsprechenden semantischen Metadaten, die aus realen Situationen nur sehr aufwendig verfügbar gemacht werden können. Wie das Beispiel oben zeigt, lassen sich mit CARLA gezielt Schwächen in KI-Komponenten identifizieren, die sich mit einem Nachtrainieren des Modells beheben lassen können.
 Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS
Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS