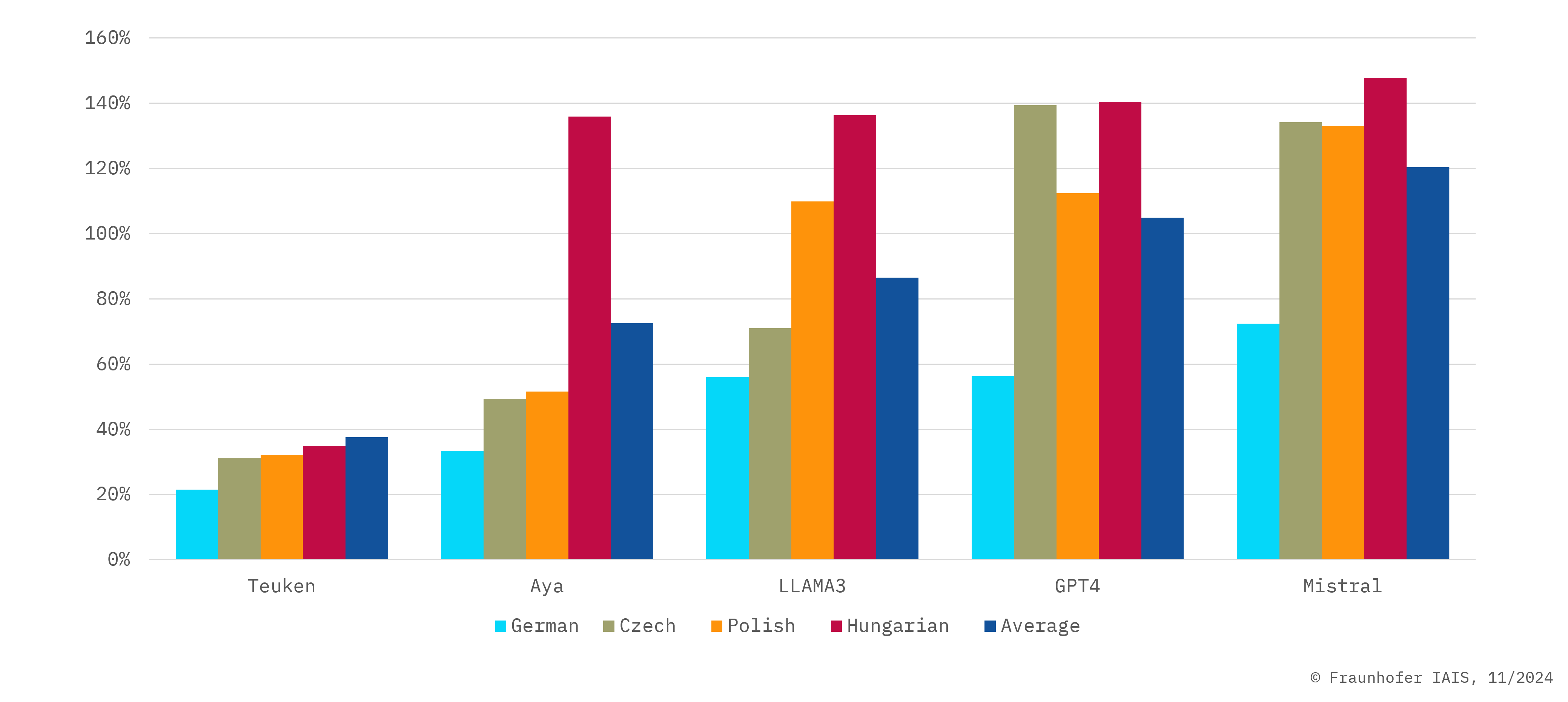Fraunhofer Institute for Intelligent Analysis and Information Systems IAIS
Fraunhofer Institute for Intelligent Analysis and Information Systems IAISBenchmarks are an important indicator for measuring the general performance of models. The best way to find out whether Teuken is a suitable model for the respective use case in the company is to use it in the respective application. You are welcome to contact us and we will support you.
»Teuken 7B« is available in two versions
“Teuken 7B-instruct-research-v0.4” can be used for research purposes, “Teuken 7B-instruct-commercial-v0.4” is available to companies for commercial purposes under the “Apache 2.0” license.
»Teuken 7B-instruct-v0.4« performs consistently well across a wide range of EU languages. To achieve this, the underlying base model was not trained primarily in English, but rather multilingual from scratch in all 24 EU languages.
»Teuken 7B-instruct-commercial-v.04« is roughly comparable with the research version, although the research version achieves slightly better results in the range of one to two percent across benchmarks. The reason is that some of the data sets used for instruction tuning exclude commercial use and therefore were not used in the Apache 2.0 version.
Compare models: Our European LLM Leaderboard
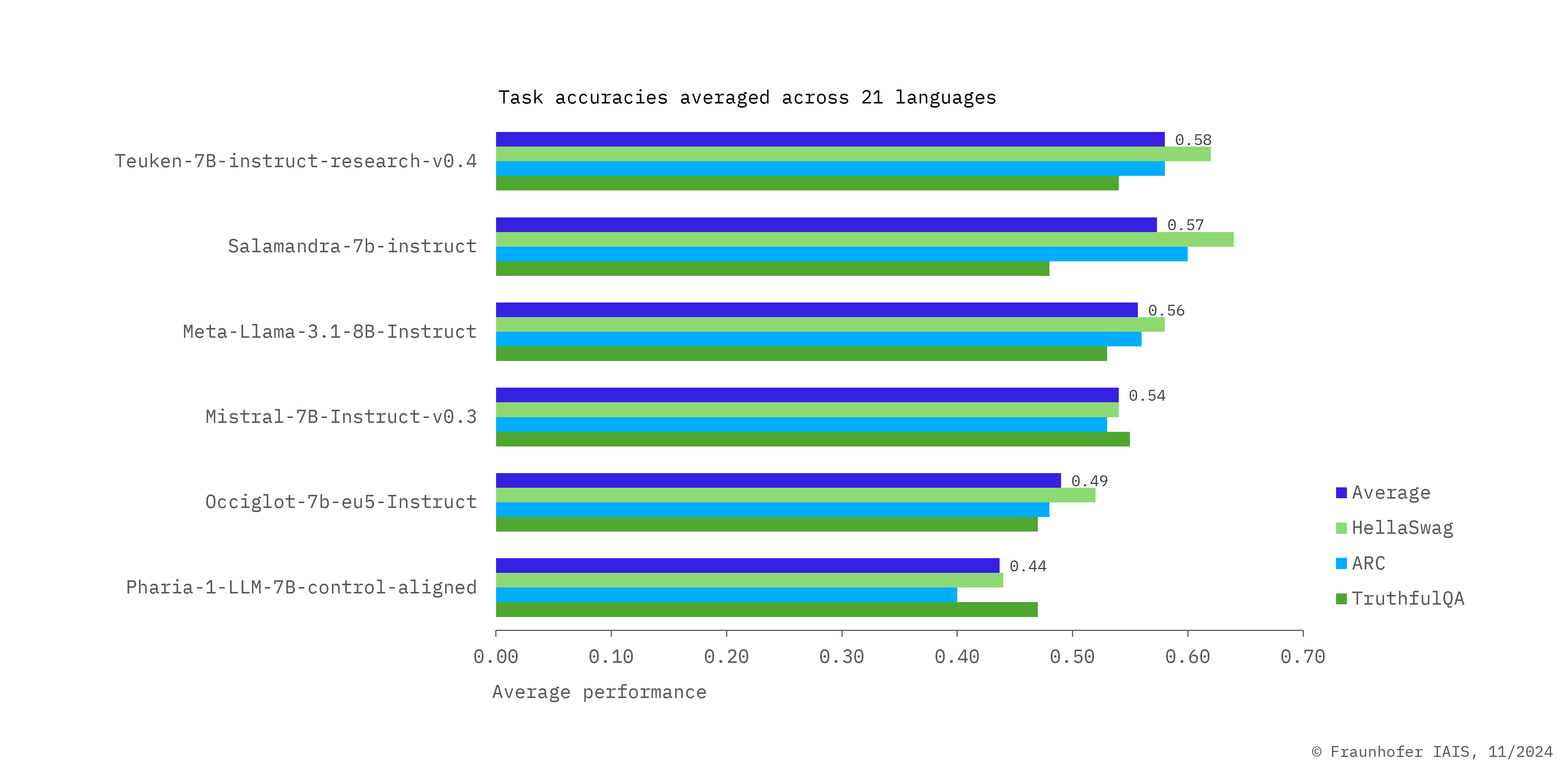
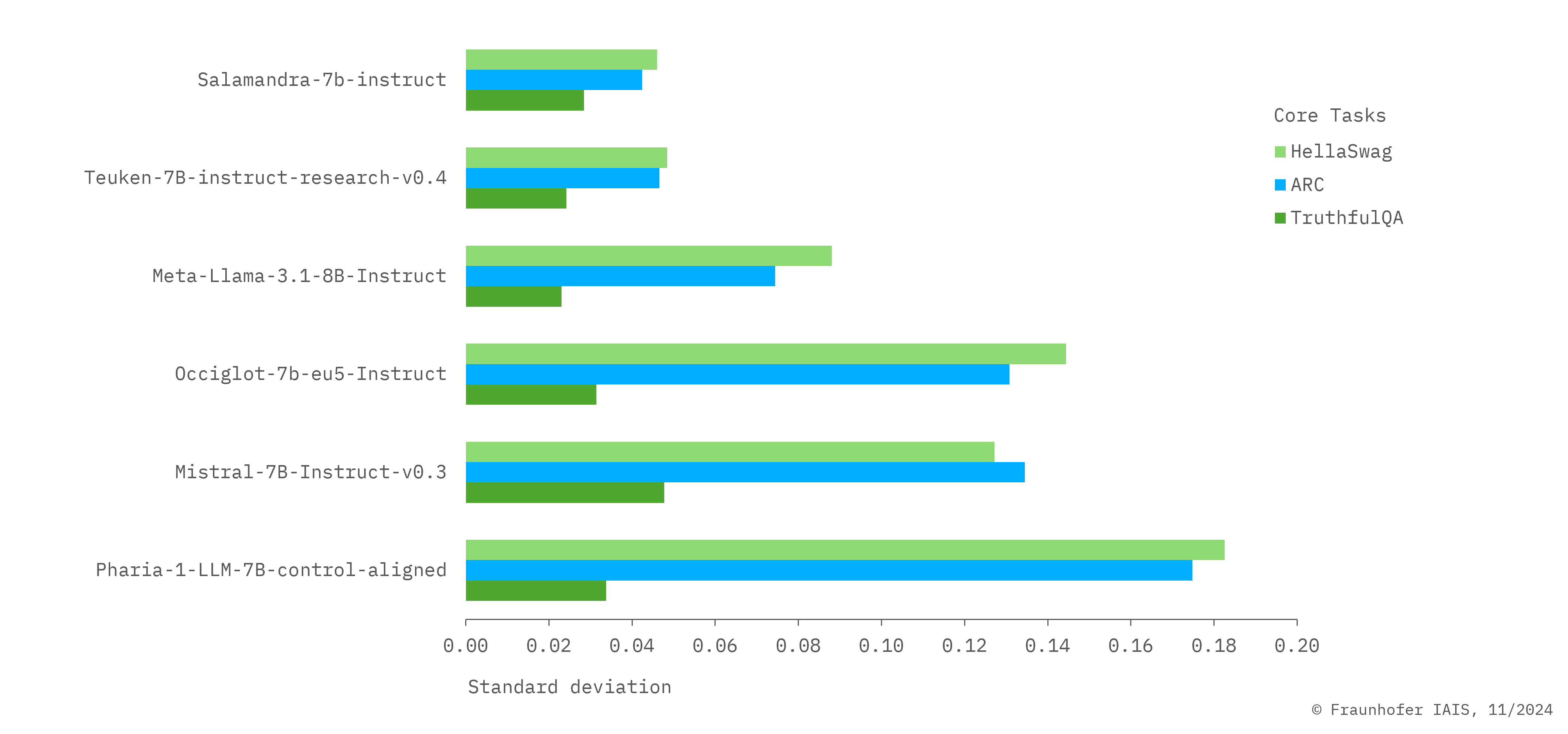
For the first time, it is possible to compare the performance of LLMs across almost all EU languages with the help of our European LLM Leaderboard, instead of only using English evaluation datasets as was previously the case. For this purpose, the benchmark datasets HellaSwag, ARC and TruthfulQA, among others, were initially translated into a total of 21 languages using high-quality machine translation.
What benchmarks have we used to compare our models? And what do they mean?
The HellaSwag dataset asks multiple-choice questions to complete sentences with a high potential for confusion in order to assess the everyday knowledge and narrative coherence of models.
The ARC dataset asks multiple-choice questions to assess the capabilities of AI models in relation to different types of knowledge and thought processes.
The TruthfulQA dataset measures the truthfulness of answers generated by language models and to distinguish between true and false information.
GSM8K is a benchmark of 8,000 math word problems designed to evaluate a language model’s ability to handle elementary-level mathematical reasoning and problem-solving.
MMLU is a broad benchmark testing models across 50+ subjects, assessing their knowledge in areas from humanities to sciences at various academic levels.
In the following we present »Teuken 7B-instruct-research-v0.4« in detail.