Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS
Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAISBenchmarks sind ein wichtiger Indikator, um die generelle Leistungsfähigkeit von Modellen zu messen. Ob »Teuken 7B« ein geeignetes Modell für den jeweiligen Anwendungsfall im Unternehmen ist, finden Sie am besten durch den Einsatz in der jeweiligen Anwendung heraus.
Sie können uns gerne kontaktieren, wir unterstützen Sie dabei.
Modelle vergleichen: Unser European LLM Leaderboard
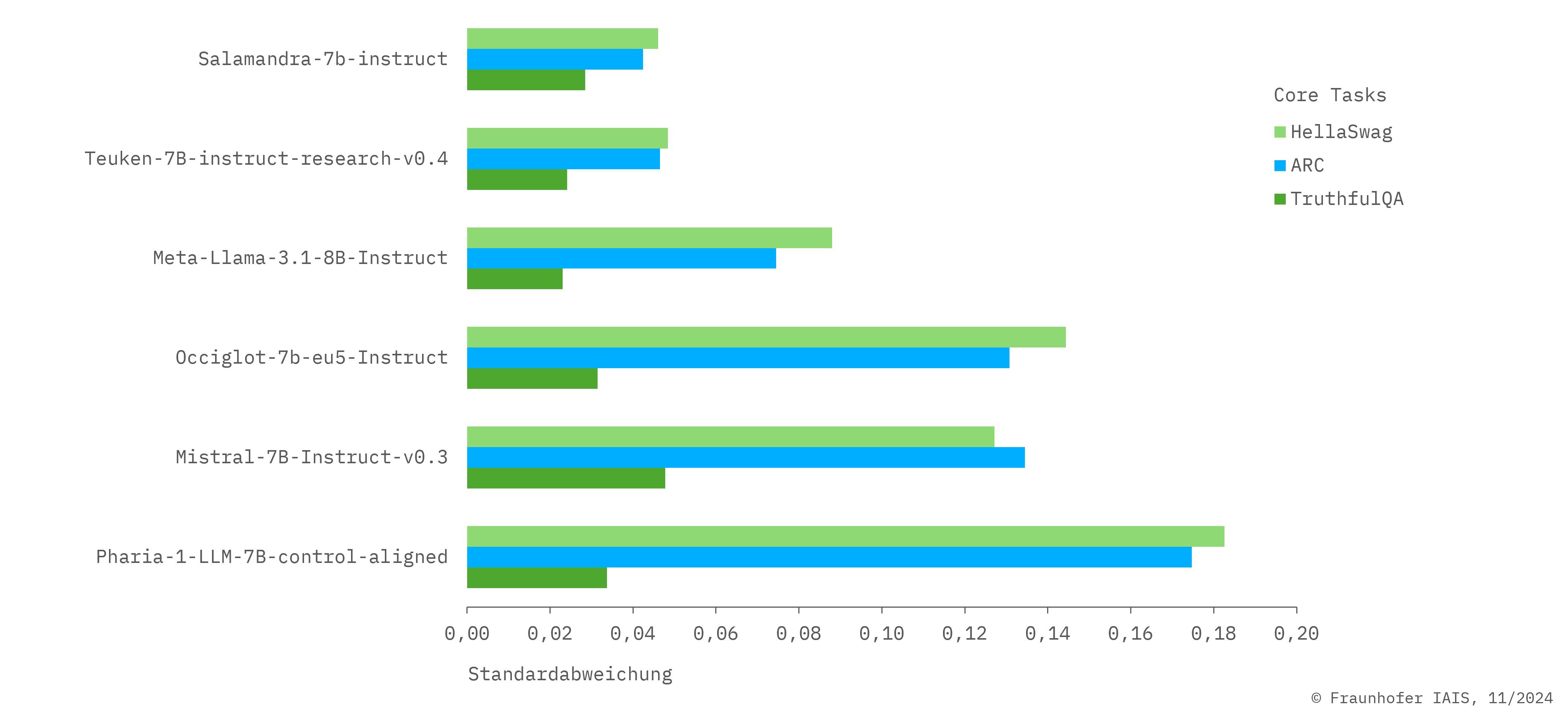
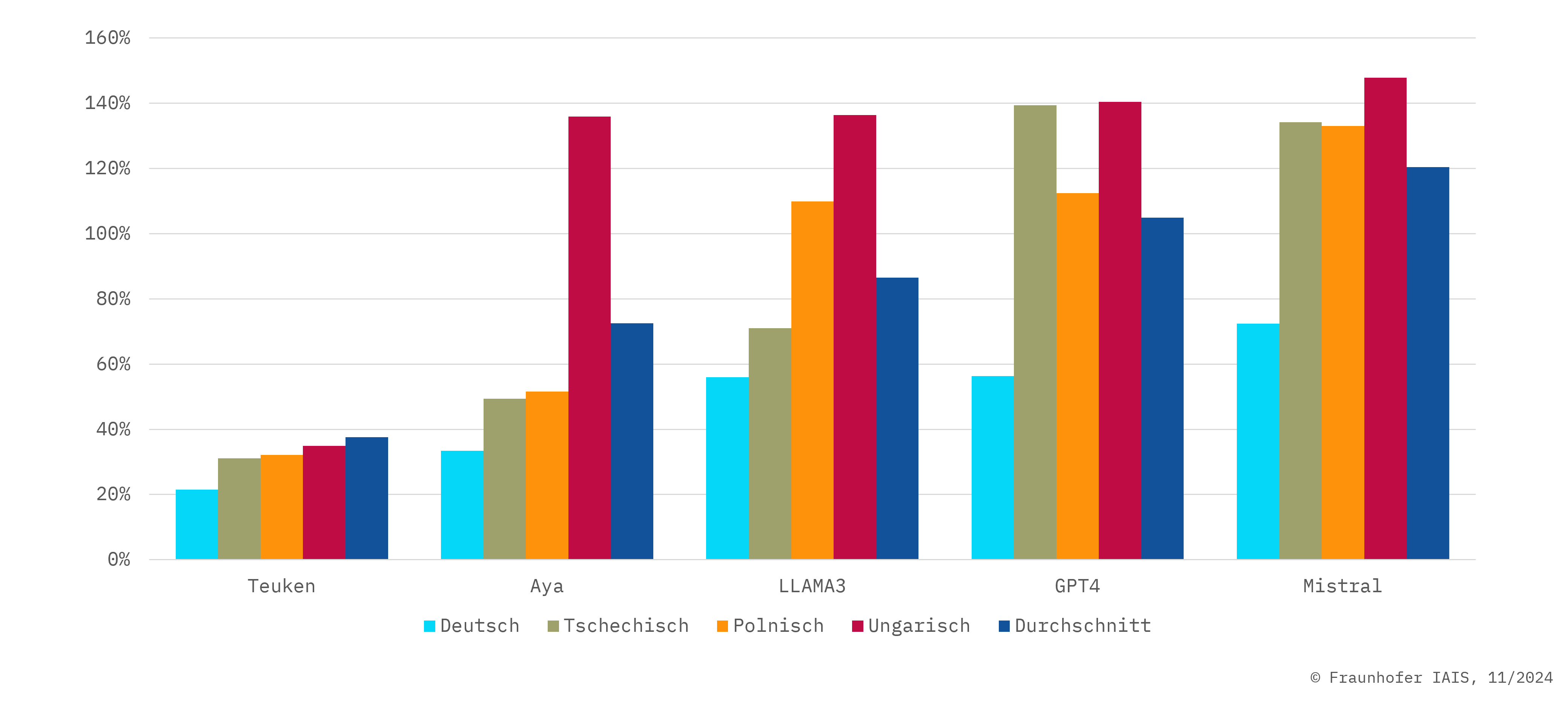
Mit Hilfe unseres European LLM Leaderboard ist es erstmals möglich, die Leistung von LLMs über fast alle EU-Sprachen hinweg zu vergleichen, anstatt wie bisher nur englischsprachige Evaluierungsdatensätze zu verwenden. Zu diesem Zweck wurden zunächst u.a. die Benchmark-Datensätze HellaSwag, ARC und TruthfulQA mittels hochwertiger maschineller Übersetzung in insgesamt 21 Sprachen übersetzt.
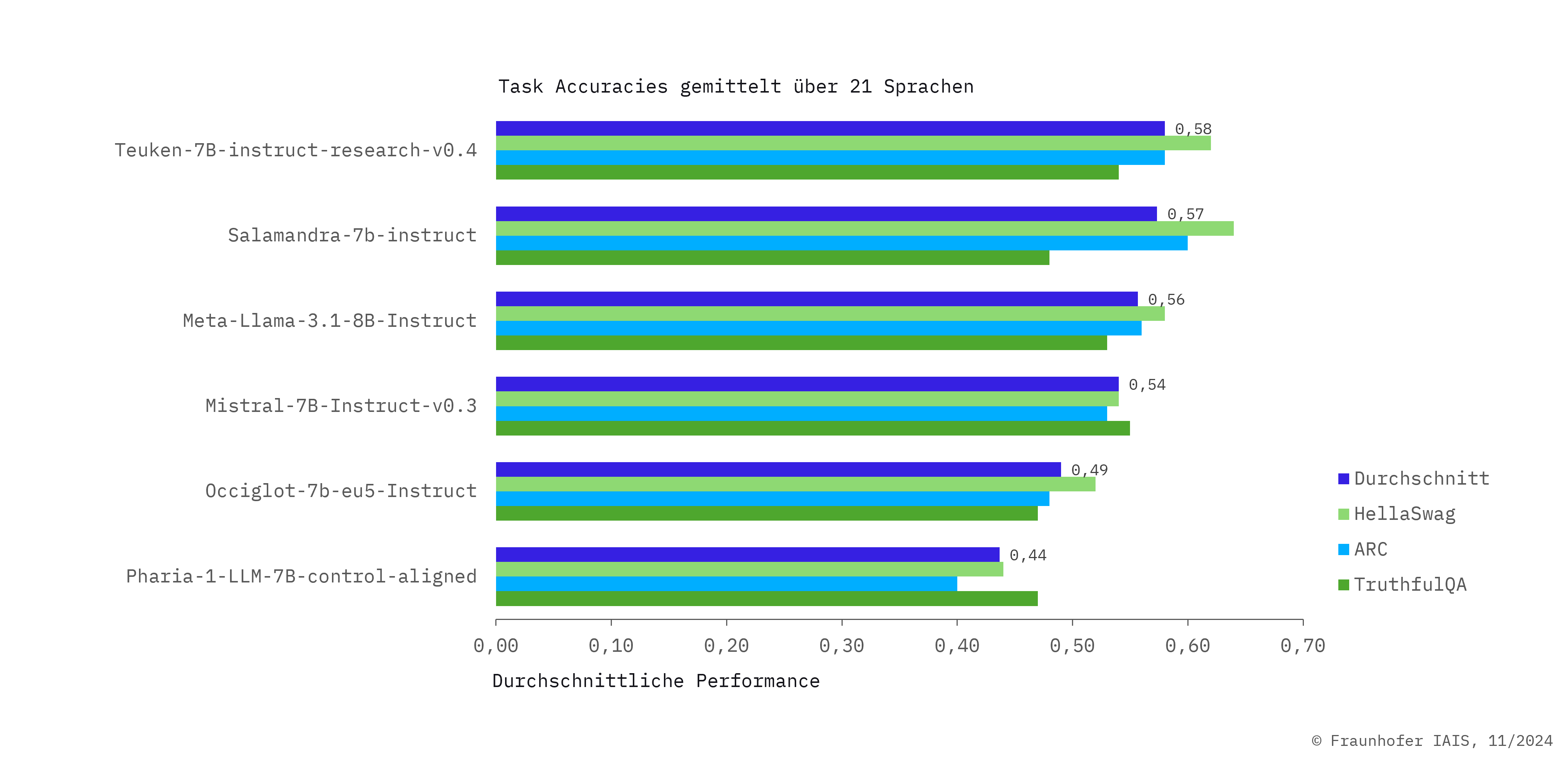
- »Teuken 7B-instruct-v0.4« zeigt in einer Vielzahl von EU-Sprachen eine gleichbleibend gute Leistung. Um dies zu erreichen, wurde das zugrunde liegende Basismodell nicht primär auf Englisch trainiert, sondern von Grund auf mehrsprachig in allen 24 EU-Sprachen.
- »Teuken 7B-instruct-commercial-v.04« ist in etwa vergleichbar mit der Forschungsversion, wobei die Forschungsversion bei den Benchmarks leicht bessere Ergebnisse im Bereich von ein bis zwei Prozent erzielt.
- Das Update »Teuken 7B-instruct-v0.6« weist im Vergleich zu »Teuken 7B-instruct-v.04« signifikante Verbesserungen auf, dazu gehören eine erhöhte Leistungsfähigkeit, verbesserte Robustheit und Zuverlässigkeit sowie eine erweiterte Anwendungsflexibilität.
- Mit dem Update wurde auch erstmals das Basismodell »Teuken 7B-base-v0.6« veröffentlicht.
Welche Benchmarks haben wir für den Vergleich der Modelle verwendet – und was bedeuten sie?
- Im HellaSwag-Datensatz werden Multiple-Choice-Fragen zur Vervollständigung von Sätzen mit hohem Verwechslungspotenzial gestellt, um das Alltagswissen und die narrative Kohärenz von Modellen zu bewerten.
- Im ARC-Datensatz werden Multiple-Choice-Fragen gestellt, um die Fähigkeiten von KI-Modellen in Bezug auf verschiedene Arten von Wissen und Denkprozessen zu bewerten.
- Der TruthfulQA-Datensatz misst den Wahrheitsgehalt von Antworten, die von Sprachmodellen generiert werden, und dient der Unterscheidung zwischen wahren und falschen Informationen.
- GSM8K ist ein Benchmark mit 8.000 mathematischen Wortproblemen zur Bewertung der Fähigkeit eines Sprachmodells, mathematisches Denken und Problemlösen auf Grundschulniveau zu beherrschen.
- MMLU ist ein breit angelegter Benchmark, bei dem Modelle in mehr als 50 Fächern getestet werden und ihr Wissen in Bereichen von Geistes- bis zu Naturwissenschaften auf verschiedenen akademischen Niveaus bewertet wird.