 Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS
Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAISTextmining für Umfangsverfahren
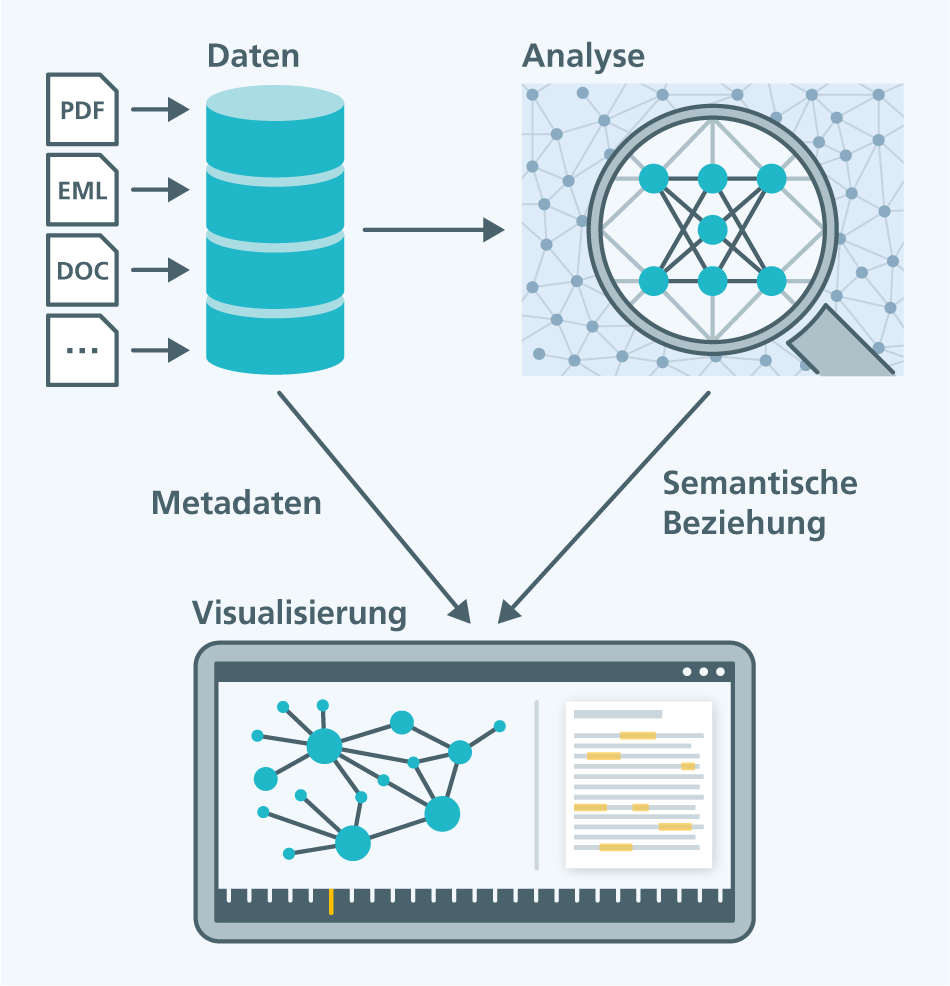
Die Auswertung von Dokumenten, E-Mails oder Chat-Nachrichten in umfangreichen Ermittlungsverfahren ist zeitintensiv. Mit Verfahren des Textminings können Effizienz und Effektivität dieser Arbeit deutlich erhöht werden.
Die Mengen der bei Privatpersonen und in Unternehmen anfallenden, elektronisch gespeicherten Daten nehmen immer weiter zu. Neben Mobiltelefonen, dem Notebook oder USB-Speichern finden sich Daten auch bei Online-Diensten wie DropBox, Google Drive oder Apple iCloud. Kommt es zu einem Ermittlungsverfahren, fallen immer häufiger mehrere Terabytes an zu analysierenden Daten an. Dabei kann es sich um Verträge, Sitzungsprotokolle, Chat-Nachrichten oder E-Mails handeln, die die beschuldigten Personen ausgetauscht haben. Allein aufgrund der enormen Menge an Daten ist es für die Ermittler kaum zu schaffen, diese Dokumente zu sichten und alle Zusammenhänge zu erkennen. Technische Systeme können dabei helfen, auch große Mengen an Dokumenten interaktiv durchsuchbar zu machen. Darüber hinaus können moderne Verfahren der Künstlichen Intelligenz auch nicht-offensichtliche Zusammenhänge zwischen Dokumenten finden und Ermittler damit dabei unterstützen, wirklich alle relevanten Hinweise zu identifizieren.
Semantische Analyse
Der hier beschriebene Demonstrator „Intelligente Textanalyse zur Auswertung von Dokumenten bei Umfangsverfahren“ verwendet Verfahren aus dem Bereich des Maschinellen Lernens und der Künstlichen Intelligenz, um zunächst automatisch alle relevanten Named Entities (Orte, Personen, Organisationen, ...) sowie Schlüsselworte und -wortketten zu identifizieren. Zusammen mit Metadaten wie E-Mail-Adressen wird nun gelernt, in welchem Zusammenhang die einzelnen Begriffe stehen. Ein sehr vereinfachtes Beispiel hierfür ist:
Das System erkennt „Herr Schmidt taucht häufig zusammen mit dem Schlüsselwort Salvato auf“. Ein Dokument, in dem Salvato auftaucht, aber nicht Herr Schmidt, ist nun trotzdem relevant für die Ermittlung zu Herrn Schmidt.
Mit dieser Technologie ist es möglich, sich bei großen Dokumentenmengen einen Überblick über die relevanten Personen, Schlüsselworte, Wortketten, Organisationen und Orte zu verschaffen und in welchen Beziehungen sie zueinander stehen. Die Analyse der Beziehungen basiert dabei allein auf den Informationen, die in der Menge der Dokumente enthalten sind. Eine manuelle Analyse im Vorfeld oder eine Anpassung der Technologie auf einen neuen Dokumentensatz ist nicht notwendig.
Interaktive Visualisierung
Neben der Technologie zur Identifikation nicht-offensichtlicher Zusammenhänge von Dokumenten zeigt der Demonstrator auch, welche Möglichkeiten eine interaktive Visualisierung den Ermittlern bei der Analyse großer Datenmengen bietet. Dazu können die Dokumente sowohl auf Basis ihrer Metadaten (Zeit, Ort, Absender, ...) als auch aufgrund ihrer Ähnlichkeit (Ergebnis der semantischen Analyse) visualisiert werden. Die Auswertung startet bei einem vom Anwender bezeichneten, spezifischen Dokument, einem der identifizierten Schlüsselworte oder einem bestimmten Zeitpunkt. Ausgehend von diesem Startpunkt werden alle hiermit in Zusammenhang stehenden Dokumente dargestellt. Die Visualisierung der Zusammenhänge richtet sich dabei nach ihrem Typ. Zeitliche Zusammenhänge werden anders visualisiert als semantische Zusammenhänge. Der Ermittler kann über die Schlüsselworte direkt auf die dahinter liegenden Originaldokumente zugreifen und sich ein eigenes Bild der Sachlage verschaffen. Die anzuzeigenden Daten können durch den Ermittler interaktiv gefiltert werden.
Die Fähigkeiten des Demonstrators werden anhand des sogenannten „Enron Corpus“ gezeigt. Hierbei handelt es sich um einen Datensatz mit über 600.000 E-Mails, die von insgesamt 158 unterschiedlichen Mitarbeitern der Enron Corporation verfasst wurden. Diese E-Mails wurden im Jahr 2002 im Rahmen der Ermittlungen zur Enron-Pleite von den Ermittlungsbehörden beschlagnahmt und nach Abschluss durch die Federal Energy Regulatory Commission veröffentlicht.